
Statystyki strefowe (Zonal statistics) w R
Statystyki strefowe to pomocne narzędzie pozwalające na wyznaczenie dowolnej statystyki z pikseli rastra pokrywających się np. z poligonem z warstwy wektorowej. Najczęściej w oprogramowaniu GIS mamy domyślnie do wyboru kilkanaście statystyk np. maksymalna, średnia, minimalna wartość itp. A co w przypadku gdy chcemy obliczyć statystykę wymyśloną przez nas. W oprogramowaniu GIS nie jest to niemożliwe, ale wymaga sporo pracy, np. z wykorzystaniem Modelera. Na szczęście mamy R-a, gdzie można to zrobić w jednej funkcji:) Zacznijmy jednak od prostych rzeczy. Inicjujemy bibliotekę raster w której znajduje się funkcja extract, służąca do ekstrakcji wartości pikseli rastra leżących w danym wektorze:
|
1 2 |
install.packages(‘raster’) library(raster) |
Inicjujemy bibliotekę rgdal, którą wykorzystamy do wczytania danych wektorowych:
|
1 |
library(rgdal) |
Wczytujemy plik rastrowy oraz plik z warstwą wektorową np. z darmowych warstw udostępnianych przez CODGiK (w moim przypadku NMT i warstwa powiatów województwa mazowieckiego):
|
1 2 3 |
r = raster(“C:/grid_mazowieckie.tif”) g = readOGR(“C:/”,”powiaty_maz”) |
Wczytane warstwy wyglądają następująco:
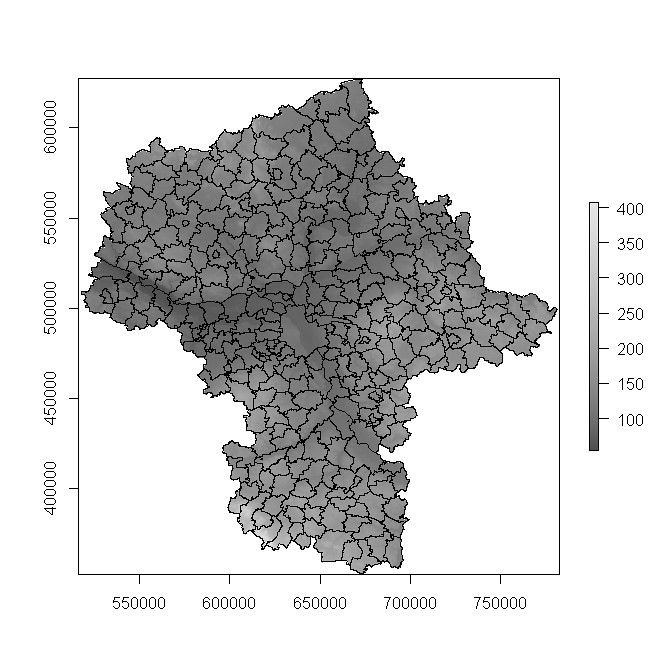
Używając funkcji extract z biblioteki raster możemy wyciągnąć wartości pikseli NMT znajdujących się wewnątrz np. dwóch pierwszych powiatów:
|
1 |
h = extract(r,powiaty[1:2,]) |
Utworzona zmienna h jest listą, zawierającą w poszczególnych elementach wartości wysokości dla konkretnego powiatu. Wartości te wywołujemy używając:
|
1 2 3 |
h[[1]] [1] 98.47 98.97 99.38 99.85 99.68 99.31 |
W przypadku, gdy dla konkretnego powiatu chcemy policzyć np. średnią wartość wysokości musimy dodać do funkcji extract atrybut fun = mean:
|
1 |
h_mean = extract(r,powiaty[1:2,],fun=mean) |
Wywołując w konsoli zmienną h_mean widzimy, że jest to już macierz wartości:
|
1 2 3 4 |
h_mean [,1] [1,] 119.7398 [2,] 119.0318 |
Jako atrybut fun do funkcji extract możemy wstawić dowolną funkcję utworzoną przez nas. Pamiętamy, że dla każdego z powiatów otrzymujemy wektor wartości i będziemy go musieli przetwarzać. Zdefiniujmy funkcję tworzącą statystykę, która będzie nam zwracała procent pikseli o wartościach większych od średniej wysokości w powiecie. Najpierw utworzymy funkcję nasza_funkcja zawierającą tylko jedną zmienną lokalną x będąco naszym zbiorem wartości pikseli oraz argument logiczny na.rm odpowiedzialny za usuwanie wartości NA:
|
1 2 3 |
nasza_funkcja function(x,na.rm=TRUE) { |
Dodajmy do funkcji zmienną zawierającą wartość średnią
|
1 |
avg = mean(x) |
Policzmy ile jest wszystkich pikseli:
|
1 |
all = length(x) |
i policzmy ile jest tych większych od avg:
|
1 |
more_than_avg = sum(x › avg) |
policzmy procent:
|
1 |
prc = (more_than_avg/all)*100 |
Funkcja będzie zwracała procent:
|
1 |
return(prc) |
Zamykamy definicję funkcji:
|
1 |
} |
Nasza funkcja ostatecznie powinna wyglądać następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
nasza_funkcja function(x,na.rm=TRUE) { avg = mean(x) all = length(x) more_than_avg = sum(x›avg) prc = (more_than_avg/all)*100 return(prc) } |
W celu wyznaczenia wartości procentów wstawiamy ją do funkcji extract do atrybutu fun:
|
1 |
pix_prc = extract(r,powiaty[1:2,],fun=nasza_funkcja) |
W wyniku otrzymujemy macierz zawierającą procenty ze zdefiniowanej przez nas funkcji:
|
1 2 3 4 5 |
prc_pixeli [,1] [1,] 46.52973 [2,] 38.13020 |
Funkcję extract możemy modyfikować w zależności jakie dane chcemy uzyskać. Polecam zajrzeć do dokumentacji technicznej tej funkcji, lub do pomocy:
|
1 |
help(“extract”) |
